
爬取某图片网站
前言
先放图看看这个网站的图片质量
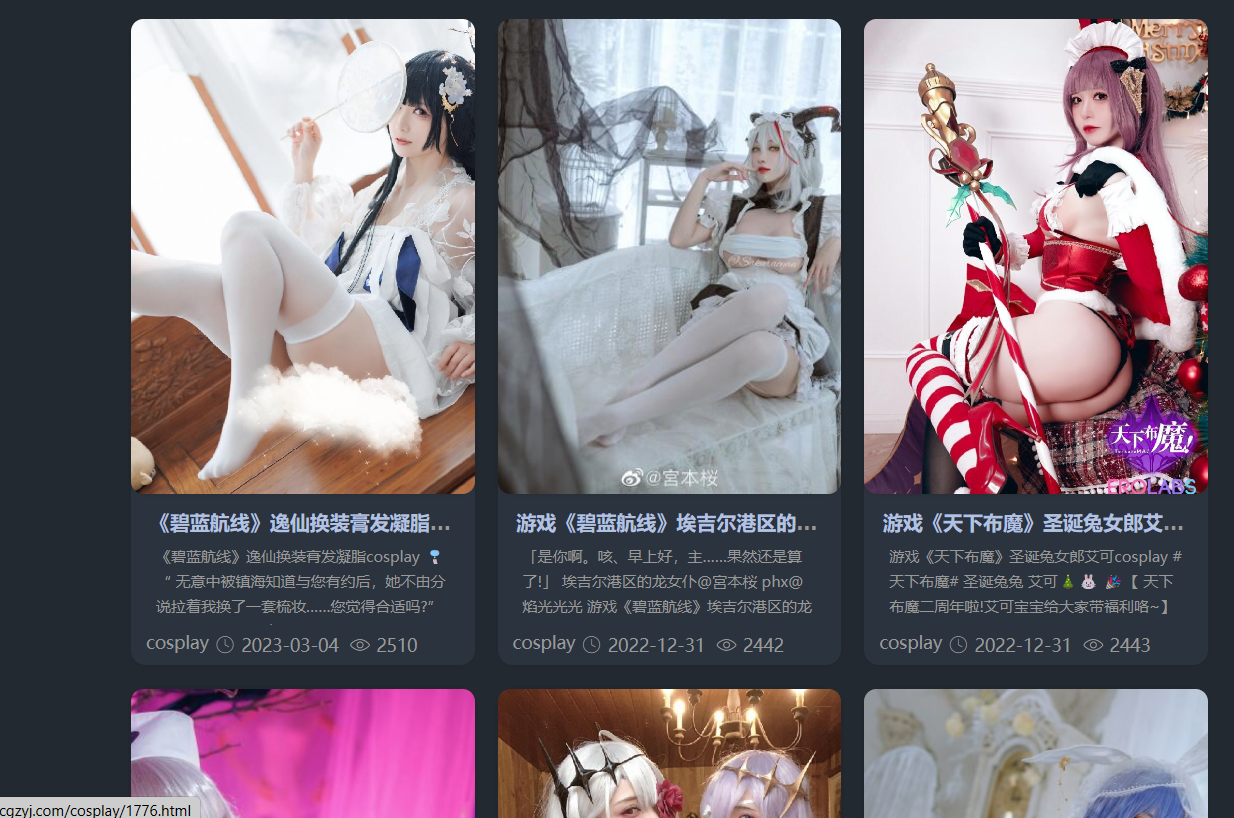

真不错,一个一个下太麻烦了,直接用python全部下载下来,网站总共应该有2000多张图片,全给他爬下来。
注意,这个网站用了ip反爬,所以需要用到ip池,不然爬几张图片ip就被封了
上代码!!!
首先用到的库
import os.path
import random
import requests
import re
from lxml import etree
import threadpool
请求头,路径、会话配置
href = 'http://www.acgzyj.com'
headers = {
'Accept': 'image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Host': 'www.acgzyj.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58',
}
session = requests.session()
count = 0
下载图片函数
def get_img(src):
hrefs = ''
if src.count('http') > 0:
hrefs = src
else:
hrefs = href+src
img = session.get(hrefs, headers=headers, proxies=proxies)
path = './imgs/'
if not os.path.exists(path):
os.makedirs(path)
with open(path+src.split('/')[-1], 'wb') as f:
f.write(img.content)
print(src.split('/')[-1]+" "+"下载完成")
获取图片地址函数
def img(hrefs):
html = session.get(href+hrefs, headers=headers, proxies=proxies)
html.encoding = 'utf-8'
html = etree.HTML(html.text)
srcs = html.xpath('//*[@id="mainbox"]/article/div[3]/p[position()>9 and position()<18]/img/@src')
pool = threadpool.ThreadPool(3)
src = [item for key, item in enumerate(srcs)]
tasks = threadpool.makeRequests(get_img, src)
[pool.putRequest(task) for task in tasks]
pool.wait()
主函数
def main(li):
headers['Referer'] = f"http://www.acgzyj.com/tuku_{li}"
html = session.get(f"http://www.acgzyj.com/cosplay_{li}/", headers=headers, proxies=proxies)
html.encoding = 'utf-8'
html = etree.HTML(html.text)
img_href = html.xpath('//*[@id="mainbox"]/div[1]/ul/li/a/@href')
pool = threadpool.ThreadPool(3)
hrefs = [item for key, item in enumerate(img_href)]
tasks = threadpool.makeRequests(img, hrefs)
[pool.putRequest(task) for task in tasks]
pool.wait()
if __name__ == '__main__':
for i in range(1, 23):
main(i)
解析一下为什么range(1,23),因为网站页面只有22页,然后这个python中的range参数1和2表示从1开始到
22,所以会执行22次。
ip池设置
# 提取ip
resp = requests.get("这是返回ip池列表的url,如果你有直接用列表存就行")
ip = resp.text
if re.match(r'(?:(?:25[0-5]|2[0-4]\d|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d\d?)', ip) is None:
exit("IP 不正确")
ip = ip.split('\r\n')
ip_addr = random.choice(ip)
ip_list = []
for ip_addr in ip:
ip_arr = ip_addr.split(":")
if ip_arr[0] == '':
continue
# 代理服务器
proxyHost = ip_arr[0]
proxyPort = ip_arr[1]
proxyMeta = "http://%(host)s:%(port)s" % {
"host": proxyHost, # ip地址
"port": proxyPort, # 端口
}
proxies = {
"http": proxyMeta,
"https": proxyMeta
}
然后可以发现请求时添加了proxies参数,这是指定ip池的,然后我还是放一下如何设置ip池把,至于怎么获取就交给你们了。
上述代码就是简单的处理了一下,把ip变成http://ip地址:端口号的形式而已,然后存放在proxies中。
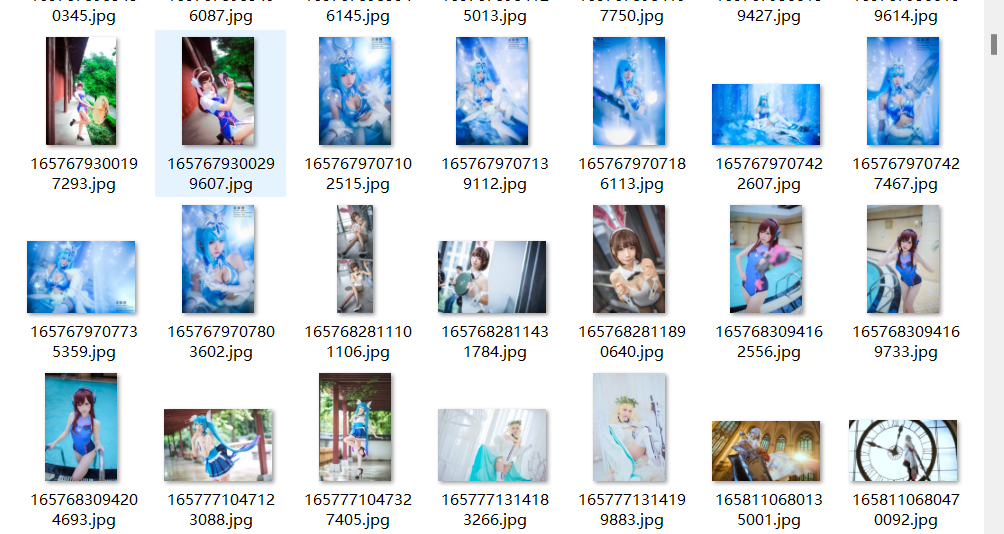
爬取结果
声明
该代码只用于学习爬虫,不会影响网站正常访问。
想知道网站地址的私信我,或者评论都行~